
Rasteret: A Library for Faster and Cheaper Open Satellite Data Access


Happy New Year, Everyone!
It’s been just over a month since we published our last blog describing a method that improves reading of Cloud-Optimized GeoTIFFs (COGs). Over the New Year break, we worked on open-sourcing not just the core logic but also creating a library with simple high-level APIs to make it easier for users to adopt our approach.
While the library is still in its early stages, we believe it can benefit geospatial data scientists and engineers significantly. By sharing it now, we hope to receive feedback and contributions via GitHub Issues and PRs to make it even more useful for the community.
Performance Snapshot: Rasterio vs. Rasteret
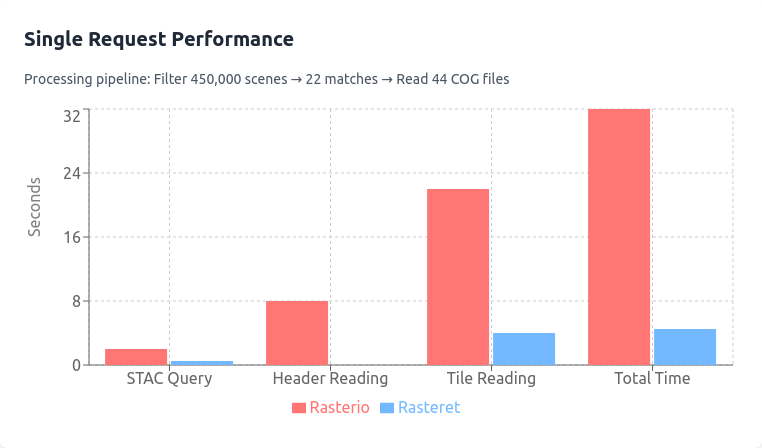
Here’s an exciting stat to illustrate the potential of Rasteret:
- 1-Year NDVI Time Series of a Farm Using Landsat 9
- Rasterio (Multiprocessing): 32 seconds (first run), 24 seconds (subsequent runs with GDAL caching).
- Rasteret: Just 3 seconds—every time.
- Even Google Earth Engine, takes 10–30 seconds for its first run and 3–5 seconds on its subsequent runs.
How was it made ?
Inspired by Kerchunk, Rasteret uses a cache to speed up COG file processing.
We call this cache, "Rasteret Collection", which is familiar to most folks using STAC. It only caches the COG file headers, it does not cache Overviews or image data tiles.
We decided to go with STAC-GeoParquet as its base, and extend it with "per-band-metadata" columns.
"For example, a Landsat Rasteret Collection is an exact copy of the landsat-c2l2-sr STAC Collection, with additional columns in the GeoParquet. If you wish to know more, check out our first blog.
What does this cost ?
In this blog we focus specifically on paid datasets like Landsat on AWS to emphasise cost savings, free STAC endpoints like Earth Search's sentinel-2-l2a is also possible to be cached with Rasteret.
Global Landsat Rasteret Collection (1 year):
- Time: ~30 minutes
- Cost: $1.8 (AWS S3 GET requests).
Regional Rasteret Collection (e.g., Karnataka, India, 1 year):
- Time: ~9 seconds
- Cost: Negligible.
Rasteret library as of now, defaults LANDSAT to the landsat-c2l2-sr collection
Creating such Collections means, you pay the cost once upfront. More on costs below.
Why We Built This Library
Intro
You can skip reading this intro section if you know the inner workings of Rasterio/GDAL.
The Hidden Performance Bottleneck For Rasterio, and its backend GDAL functions, getting image data involves quite a few rounds of metadata retrieval. Here's what happens behind the scenes:
- First HTTP Request: Fetch file header
- Retrieves critical metadata like CRS, Transform
- Caches this information in-memory or on disk using GDAL's cache
- Additional Requests: Grab COG overviews
- Useful for quick visualizations
- But... it means more HTTP requests to the same file
Then, when you call -
from rasterio.mask import mask
data, transform = mask(src, [geometry], crop=True)Rasterio now uses its cached info in GDAL to:
- Determine which image tile is in which byte-range
- Make final HTTP requests to fetch the numpy array
The Real Cost: Between 3 to 6 HTTP requests per .tif file, every time you start a new Python environment.
Effect of New Environments on GDAL Cache
It is important to note that GDAL cache helps to reduce the HTTP requests to COG files, if your code is re-run in the same environment/session.
Where GDAL cache remains -
- Rerunning the same '.py' file
- Consistent Jupyter notebook sessions
- Long-running Cloud VMs
- Local Python environments in laptop
Where GDAL cache is lost/non-existent -
- Laptop or VM restarts
- Cloud-native workflows with scaling VMs
- Hosted Jupyter notebooks kernel or VM restarting
Era of cloud native geospatial workflows
In today's cloud-based data analysis, we leverage cloud elasticity like never before:
- Multiple compute machines (VMs)
- Serverless platforms (AWS Lambda, GCP Cloud Run)
- Kubernetes orchestrators (Airflow, Kubeflow, Flyte)
The Catch: Each of these creates a NEW Python environment.
Translation: Rasterio must re-fetch metadata for EVERY COG file, every single time.
With workflows that depend on thousands of files and highly parallel tasks, this inefficiency can quickly escalate.
Rasteret addresses these limitations, and ensures consistent performance and cost efficiency, even in distributed, and ephemeral cloud environments.
Cost and Time Analysis - Rasteret vs Rasterio/GDAL
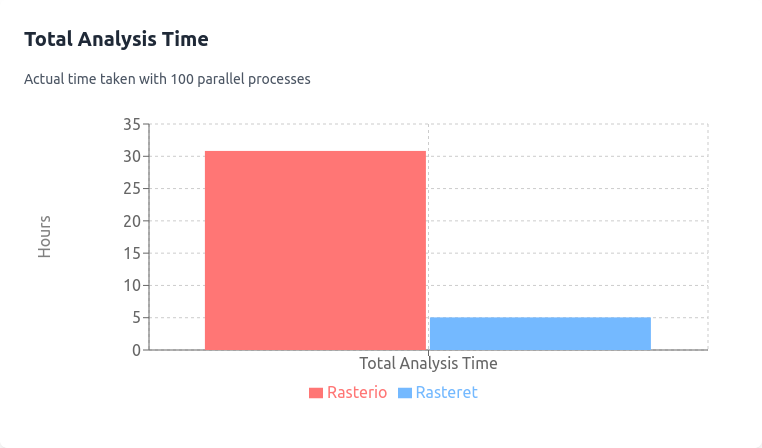
Let’s break down the cost and time differences for a hypothetical project analyzing 100,000 farms. The project needs time-series indices of various kinds like NDVI, NDMI etc.
Here’s the scenario:
- Scenes: 2 Landsat scenes covering all farms.
- Dates per scene: 45.
- Bands to be read per date: 4.
- Total files: 2 × 45 × 4 = 360 COG files.
- Files worth processing (due to cloud cover): 200 COG files.
Workflow
- Rasteret caches metadata for the 200 files in its Collection, and its used across 100 parallel processes (dockers/lambdas).
- Rasterio/GDAL reads headers repeatedly in new environments due to lack of shared cache
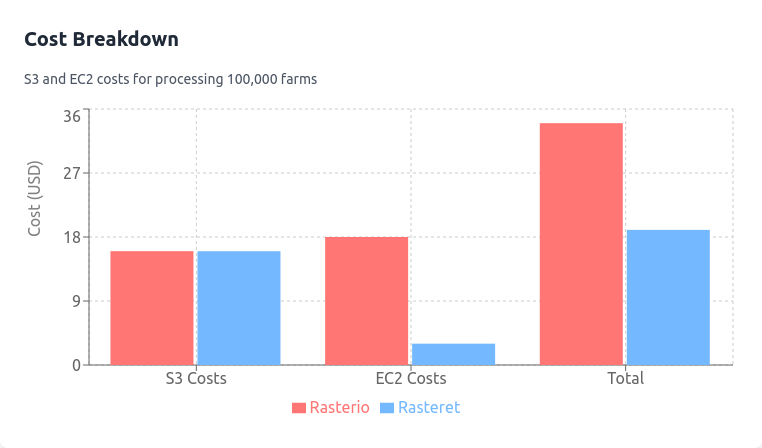
S3 GET Costs for Header Reads
- Rasteret:
- Cache headers once: 200 requests(1 per file) × $0.0004/1000 = $0.00008.
- Rasterio/GDAL:
- Headers read 100 times (100 processes): 100 × $0.00008 = $0.008.
S3 GET Costs for Image Tile Reads
- Both Rasteret and Rasterio:
- 100,000 farms × 2 images tiles cover per farm × 200 files × $0.0004/1000 = $16.
Total S3 Costs
- Rasterio: $16 + $0.008 = $16.008.
- Rasteret: $16 + $0.00008 = $16.
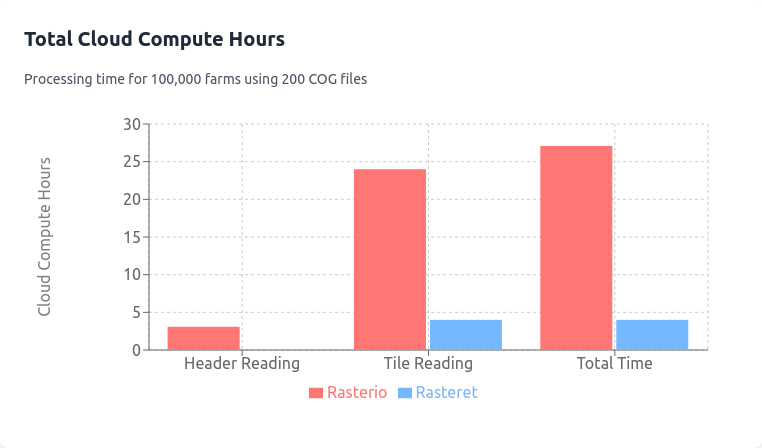
EC2 Costs
Assume t3.xlarge AWS SPOT type instances at $0.006 per hour:
- Rasterio Processing Time:
- Files processed per second: 1.8.
- Total VM time: 200 files / 1.8 × 100,000 farms = 11,100,000 seconds.
- Time for parallel process = 11,100,000/100/3600 = 30 hours
- EC2 cost: 11,100,000 / 3600 × $0.006 = $18.
- Rasteret Processing Time:
- Files processed per second: 11.
- Total VM time: 200 files / 11 × 100,000 farms = 1,818,000 seconds.
- Time for parallel process = 1,818,000/100/3600 = 5 hours
- EC2 cost: 1,818,000 / 3600 × $0.006 = $3.
Total Costs
- Rasterio: $16.008 (S3) + $18 (EC2) = $34.008.
- Rasteret: $16 (S3) + $3 (EC2) = $19.
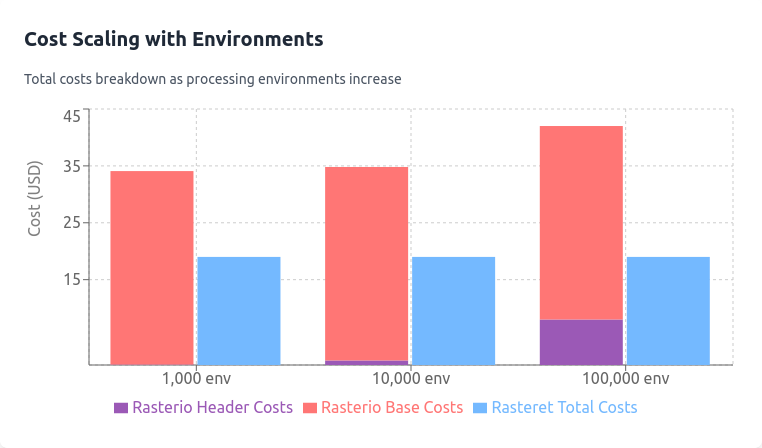
Scalability and Repeatability
By running more such workflows parallely, doing EDA on same or different set of farms, the long term implication is that for each run without a GDAL cache, using Rasterio, costs rise due to repeated header reads:
- 1,000 environments: $34.008 + $0.08 = $34.088.
- 10,000 environments: $34.008 + $0.8 = $34.808.
- 100,000 environments: $34.008 + $8 = $42.008.
Rasteret’s cached metadata in Collection ensures consistent costs for the above scenarios.
Conclusion
Rasteret is not intended to replace GDAL or Rasterio, which are amazingly feature rich libraries. Rather, it is focused on addressing a critical aspect of making cloud-native satellite imagery workflows faster and cheaper."
This is an early release of the library, which we shared because its performance and efficiency seem promising. But we want eyes on it early. Do give us your feedback and ideas as issues or PRs.
There are lots of improvements that can be done, from better deployment actions, adding clear release notes, more test coverage, support for Python 3.12, and 3.13, support for S3 based Rasteret Collections, and more.
In parallel, we plan on adding features too, one of the first that we think will be useful is a PyTorch's TorchGeo compatible on-the-fly Dataset creator, for which there's an open issue as well. Do share your thoughts there.
Do try it out with Python 3.11 environment -
uv pip install rasteretIf you like it, do give us a ⭐ on Github, if you have already installed it, do upgrade it.
Thanks for reading till the end, wish you have a wonderful year ahead!
Acknowledgements
This work builds on the contributions of giants in the open-source geospatial community:
- GDAL and Rasterio, for pioneering geospatial data access
- The Cloud Native Geospatial members for STAC-geoparquet and COG specifications
- PyArrow, GeoArrow for efficient GeoParquet filtering
- The broader open-source geospatial community
We're grateful for the efforts and contributions of these projects and communities. Their dedication, expertise, and willingness to share knowledge have laid the foundation for approaches like the one outlined here.
Terrafloww is proud to sponsor the Cloud Native Geospatial forum as a small startup member



